CrystoLabs Blog
Decentralized Intelligence at CRYSTO
A CrystoLabs research blueprint for transparent, trust-minimized intelligence systems: distributed data, compute, validation, incentives, observability, and AI-addressable CRYSTO infrastructure.

Research Direction
01
CrystoLabs is the research and engineering arm inside CRYSTO. Our focus is simple to say and hard to build: systems that learn over time, stay transparent by design, and reduce the need for blind trust.
This blueprint outlines the direction of our decentralized intelligence research for engineers, builders, researchers, and readers who want to understand where CRYSTO is heading. Nothing here should be treated as production-ready.
Many components are prototypes, internal alpha systems, or research-stage designs, and details will evolve through experiments, audits, and development.
AI-Addressable Infrastructure
02
CrystoLabs is not trying to build a blockchain only for AI. We are building CRYSTO as a general-purpose execution and coordination layer that AI systems can interact with.
Think of it as AI-addressable infrastructure. Instead of every decentralized application being created, managed, and operated only through manual code orchestration, AI agents and human users should eventually interact with CRYSTO through structured prompts, verified actions, and transparent execution paths.
That direction is separate from, but deeply connected to, decentralized intelligence.
Why Decentralized Intelligence Matters
03
Centralized AI is fast, useful, and convenient, but it is controlled by a small number of actors. That model becomes fragile in areas where auditability, shared control, and public accountability matter: finance, public infrastructure, health systems, autonomous agents, and protocol governance.
Decentralized intelligence explores a different model by spreading compute, data access, validation, models, and reasoning capacity across many participants. The goal is not decentralization for decoration.
The goal is intelligence that is more verifiable, inspectable, and incentive-aligned.
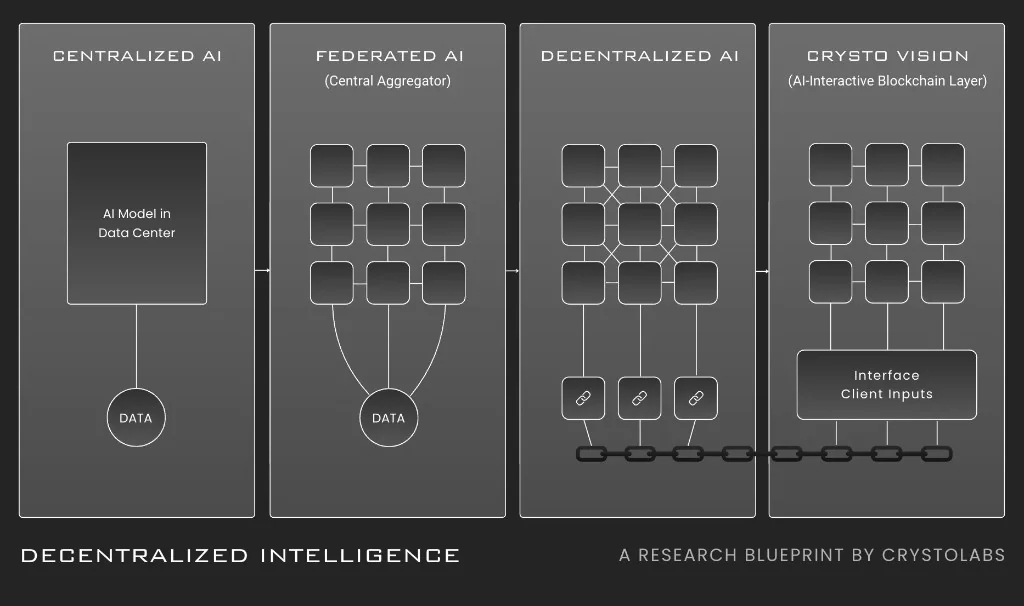
System at a Glance
04
The system is designed in layers that can evolve independently while contributing to the same intelligence network. Identity and networking establish who is participating and how reliable they are.
The data layer keeps raw data with its owner whenever possible. The compute layer supports federated learning and swarm training.
Model and task registries provide public lineage. Incentives and governance reward useful work and punish harmful behavior.
Observability makes training, inference, contribution, validation, and checkpoint history inspectable by design.
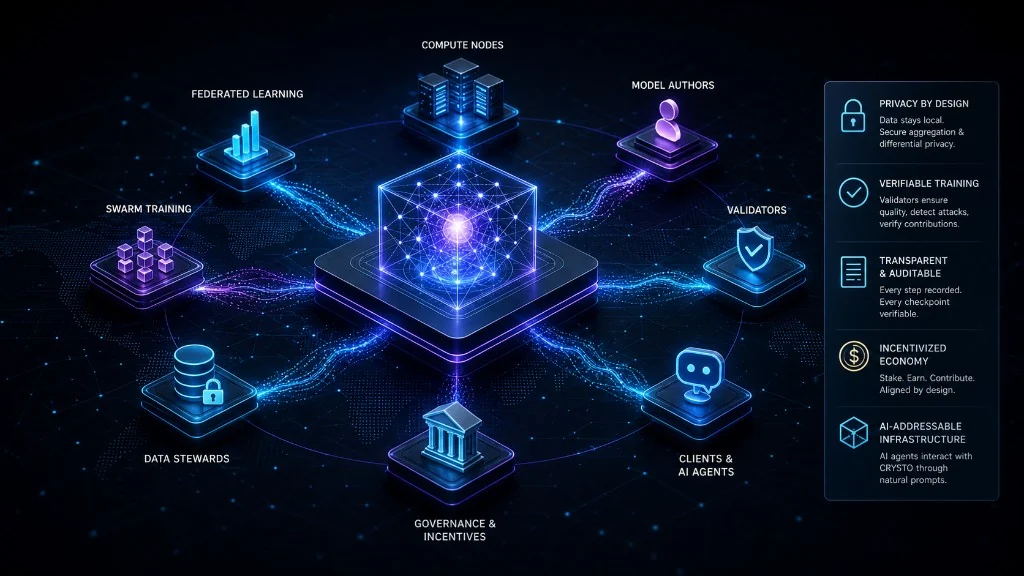
Identity, Data, and Compute
05
Participants are identified through wallet keys and coordinate through a peer-to-peer network for task discovery, scheduling, training updates, validation, and inference routing. Raw data should stay with its owner whenever possible.
Data stewards can expose controlled feature views, training hooks, or privacy-preserving endpoints instead of handing datasets to a central server.
The compute layer supports federated learning when data is distributed across owners, and swarm training when larger models need distributed GPU networks, model partitioning, pipeline parallelism, tensor parallelism, compression, scheduling, and verification.
Registry, Incentives, and Governance
06
Tasks and models need public structure. On-chain registries can map task IDs to model families, licenses, validators, reward rules, and checkpoint hashes, while larger metadata can live off-chain through IPFS or similar storage.
Participants stake to take part in the network, and rewards should follow measurable contribution rather than noise or fake activity. Governance controls protocol parameters, validator requirements, privacy settings, task policies, emergency procedures, and treasury allocation.
The economic model should reward useful work, penalize proven harm, and avoid quietly centralizing the network through incentives.
Roles in the Network
07
Different participants can contribute in different ways. Data stewards keep data local and expose feature views or privacy-preserving training endpoints.
Compute miners provide GPUs and run training or inference workloads. Model authors submit architectures, training recipes, and evaluation plans.
Validators run convergence tests, outlier filters, backdoor checks, and verification tasks. Clients consume models through gateways and pay per call, task, or subscription.
A single organization may hold multiple roles, but the protocol should not assume these roles trust each other.
Training Lifecycle
08
A decentralized intelligence task begins with a Task Spec that defines the model family, loss function, evaluation metrics, privacy level, reward weights, validator requirements, hardware rules, and security constraints.
Participants then signal interest by staking, and the scheduler forms a cohort based on stake, reputation, hardware, availability, diversity, and task requirements. In federated mode, participants train locally and submit updates.
In swarm mode, nodes handle layers, tensor slices, or pipeline stages. Accepted updates are aggregated, checkpointed, hashed, attributed, and registered with metrics and proof packages.
Verification and Rewards
09
Validators run multiple families of checks: outlier filtering, RONI tests, backdoor detection, spot-check recomputation, and validator agreement scoring. Contributions that damage performance are down-weighted or rejected, and repeated harm can trigger slashing.
Rewards should track measurable value through validation lift, data value estimates, timeliness, availability, reliability, validator agreement, and long-term contribution quality. If participants earn from a model, the network should be able to explain why.
Inference Lifecycle
10
Clients call a gateway. The router selects a healthy cluster based on model ID, latency class, cost, region, and reliability.
Nodes return signed outputs linked to a checkpoint hash. Hot contexts can be cached, and audited responses can sample duplicate inference and compare logits within tolerance.
This creates a path where inference is not only consumed, but traceable.
Security Posture
11
Security is part of the architecture, not an optional section at the end. Robust aggregation, RONI tests, spectral signatures, and trigger-set testing reduce poisoning and backdoor risk.
Stake, identity scores, device fingerprints, rate limits, reputation, and random spot checks reduce Sybil behavior. Raw data should not move unless explicitly required.
Secure aggregation hides individual updates, differential privacy can be enabled with a documented epsilon, and high-risk work can require trusted execution environments or signed data connectors.
Abuse Response and Governance Limits
12
The system needs clear playbooks. Tasks can be frozen, checkpoints can be forked, and pre-incident checkpoints can remain available while review continues.
Every fork should write its provenance. Emergency controls should be visible, time-limited, and accountable.
High-risk tasks may require stronger review, human-in-the-loop safeguards, or ethics board approval. The network should not rely on memory, panic, or private group chats when something breaks.
Observability and Service Objectives
13
A decentralized intelligence network should be treated like a live market: positions are always open, risk is always moving, and signals matter.
Early targets may include training availability of 99.5% per rolling week, inference p95 latency under target per tier, validator agreement above a defined threshold, fully traceable checkpoint lineage, and documented incident response paths before launch.
The network should track convergence curves, validator disagreement, poisoning alerts, node churn, reward distribution, epsilon usage, energy per effective step, failed validation rounds, cohort diversity, and checkpoint adoption.
What Exists in the Lab
14
Current research includes an orchestrator in Go with a Rust client, Flower and FedML adapters for federated mode, a swarm training prototype with pipeline parallelism across community GPUs, secure aggregation using threshold cryptography, optional differential privacy, an inference gateway on Ray Serve, EVM contracts for registry, staking, rewards, and slashing on testnet, and off-chain metadata on IPFS.
Model baselines include an image classifier and small language model in federated mode, experimental medium language model shards in swarm mode, and a DeFi event-stream risk classification head. Verification work includes RONI, trimmed mean, Krum, backdoor tests, and partial spot-check recomputation.
Roadmap
15
The roadmap begins with a devnet focused on single-tenant federated tasks, correctness, observability, a minimal SDK, Task Spec format, internal dashboards, basic registry flow, and an initial validation pipeline.
Testnet alpha introduces open cohorts, staking, rewards, validators, public dashboards, and optional differential privacy. Testnet beta introduces swarm mode, default gradient compression, external audits, and agent pilots.
Mainnet introduces DAO governance, compliance profiles, production service objectives, and incident runbooks. Dates remain internal and tied to stage gates.
Public updates should follow working demos, not calendar theater.
Developer Starting Point
16
A developer starts by writing a Task Spec that defines the model, loss, metrics, privacy settings, training parameters, validator minimums, and reward weights. The spec hash is registered in the registry contract.
From there, the developer implements dataset adapters, exposes feature views or training hooks, launches a training round, lets the scheduler form a cohort, streams logs and metrics, waits for validator approval, aggregates accepted updates, publishes the checkpoint hash, computes attribution and rewards, and registers the model with the inference gateway.
Risks and Limits
17
Decentralized training is slower than a private supercomputer. Verification costs real compute.
Incentives can be gamed if the math is weak. Governance can stall if proposals are unclear.
Privacy guarantees require discipline, not marketing language. These are not reasons to avoid the problem.
They are reasons to engineer carefully, publish proofs, and move in stages.
What Success Looks Like
18
Success is a network where anyone can contribute useful compute or data without surrendering control. It is a model registry where checkpoints ship with proofs, lineage, and attribution.
It is a community that earns when models improve. It is clients who can explain to auditors what a model learned, which checkpoint they used, and where the evidence lives.
CRYSTO becomes AI-addressable, so builders can operate decentralized applications through prompts when appropriate, while the chain remains general-purpose and not limited to AI-specific use cases.
Call for Collaborators
19
If you are a data steward, GPU operator, model author, validator, researcher, or builder who shares this vision, CrystoLabs wants to hear from you. We are building in the open where possible.
Early collaborators help us test the hard parts and shape the results. This document reflects research and prototypes, not production commitments.
Components vary in readiness from experimental to internal alpha. Interfaces, algorithms, incentives, and timelines may change before any mainnet release.
The direction is stable. The details will evolve.


